
Self‑hosting isn’t just a technical choice; it’s a commitment to escaping censorship, avoiding vendor lock‑in, and maintaining absolute control over your data.
Your Hardware. Your Data. Your Control.
We help you transform yesterday’s enterprise workstations into tomorrow’s AI infrastructure. That decommissioned server collecting dust? That’s your new machine learning platform. Those old workstations your company retired? Perfect for distributed AI training clusters.
Whether you need a whisper-quiet small form factor system for your home office, a full-tower beast for serious research, or rack-mountable units for production deployments—we configure it all.
Built for Real-World AI Work
This isn’t a hobby project. Our AI workstations handle:
- Local LLM deployment (Llama, Mistral, Phi) without cloud dependency
- Custom model training and fine-tuning on your proprietary data
- AI agent development with n8n automation pipelines
- Computer vision research with GPU-accelerated processing
- Engineering simulations requiring massive parallel computation
Why Businesses Choose Custom AI Labs
Security-conscious enterprises can’t risk sending sensitive data to third-party APIs. Engineers need rapid iteration without API rate limits. Researchers require reproducible environments. Startups want to control costs while scaling AI capabilities.
Our configured workstations deliver all of this using proven open-source stacks: Proxmox for virtualization, Docker for containerization, Ollama for model management, and OpenWebUI for intuitive interfaces.
The Smart Economics of Ownership
A single year of heavy ChatGPT API usage costs $5,000+. Our entry-level AI workstation? Under $2,000 with room to expand. Add GPUs incrementally as your needs grow. Scale horizontally by clustering multiple systems. No vendor lock-in. No surprise bills.
Plus, you’re not limited to someone else’s model capabilities. Want to fine-tune Llama for your industry’s specialized vocabulary? Done. Need to run multiple models simultaneously for comparison testing? Easy. Want air-gapped systems for classified research? We configure that too.
From Box to Breakthrough in Days
We don’t just ship hardware. Every system arrives configured with your chosen AI stack, tested, documented, and ready to deploy. Need custom automation workflows? We build those. Want training on self-hosting best practices? That’s included.
Three Configurations. Infinite Possibilities.
Small Form Factor: Silent powerhouse for individual researchers and home offices
Full Tower: Maximum expandability for growing AI teams and serious computation
Rack Mount: Enterprise-grade infrastructure for production deployments
Each system is customizable with CPU, RAM, GPU, and storage configurations matched to your workload.
Ready to Own Your AI Future?
Stop renting AI capabilities. Start building them. Schedule a free consultation to discuss your specific requirements, and we’ll design an AI home lab that delivers ROI in months, not years.
Your next breakthrough shouldn’t be held hostage by API limits.
-
Setting Up Ollama or LM Studio for Local LLM Inference
Both Ollama and LM Studio enable private, offline AI inference on your hardware, but they serve different user profiles. Ollama excels as a developer-focused CLI tool with powerful automation capabilities, while LM Studio offers a polished graphical interface ideal for beginners and quick experimentation. Installing Ollama Linux/macOS: Download and install Ollama with a single command:…
-
Secure Remote Access Options for Self-Hosted AI Lab
Accessing your self-hosted AI infrastructure remotely requires balancing security, ease of use, and performance. The right solution depends on your threat model, technical expertise, and whether you need to share access with team members or clients. Tailscale: Zero-Configuration Mesh VPN Tailscale provides the most user-friendly approach for secure remote access to AI workloads. It creates encrypted…
-
Hardware Checklist for Home AI Server
Building a home AI server requires careful hardware selection to balance performance, cost, and future scalability. The right components ensure smooth local LLM inference, RAG workflows, and creative AI tasks without cloud dependencies. GPU Recommendations by Use Case Use Case Recommended GPU VRAM Model Capacity Entry-level / Development RTX 3060, RTX 4060 12GB 7B-8B models…
-
Achieving Digital Sovereignty Through Self-Hosted AI and Automation
Digital sovereignty begins with reclaiming control over your data, infrastructure, and workflows. By transitioning from cloud-based services to self-hosted AI and automation stacks, individuals and organizations can achieve enhanced privacy, eliminate recurring subscription costs, and maintain complete compliance with regulations like GDPR while avoiding vendor lock-in. Core Infrastructure Components The foundation of a sovereign AI…

Stop Using “Act As A…” Immediately (Do This Instead)
Listen to me. If you are still starting your prompts with “Act as a marketing expert,” you are actively sabotaging…

The 2026 Agentic Playbook: From Jargon to Profit
Why Your Workflow is About to Break (and How to Fix It) The tech world is drowning in “Artificial General Intelligence”…

Antigravity: The Next Leap in Autonomous AI
Google Antigravity is Here: Stop Coding, Start Orchestrating The game has changed. We aren’t just talking about “smarter” autocomplete anymore. With the…
Copy of 200+ Ways to Make Money with AI (Mindstream
Tip: bookmark this page You’re All Set! You can access ‘200+ Ways to Make Money with AI’ below at any time….
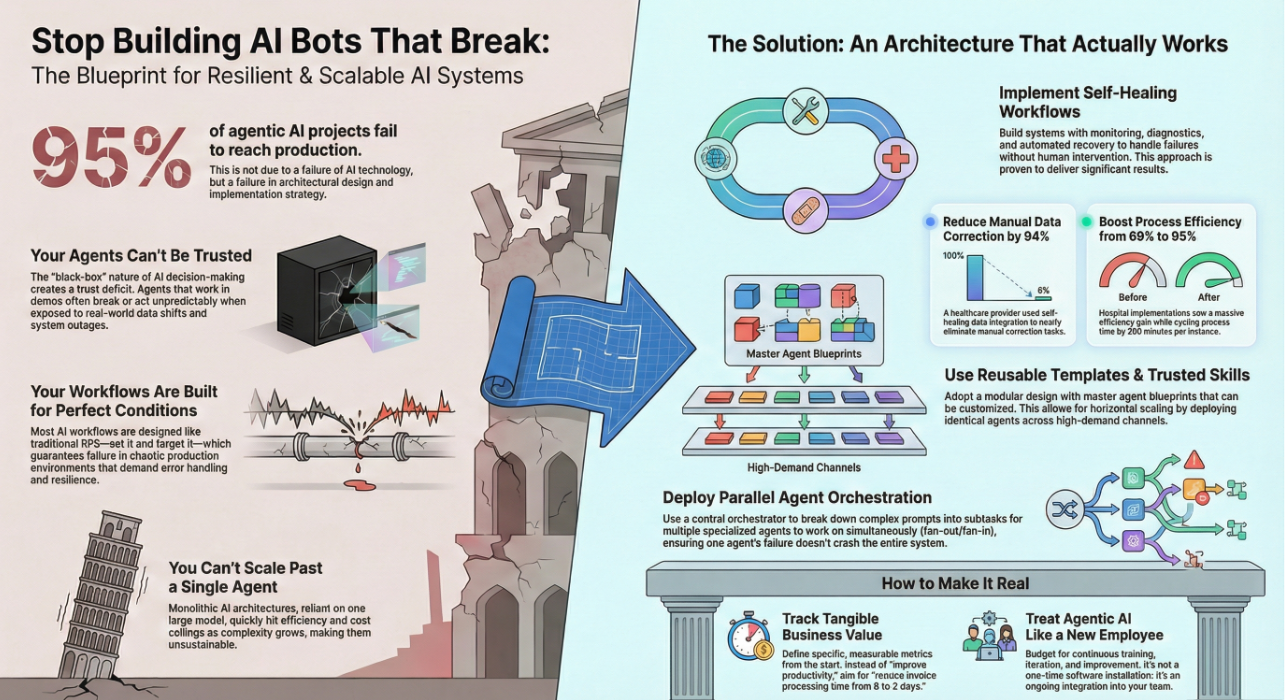
Stop Building AI Bots That Break—Here’s How to Build Systems
You’ve seen the headlines. 95% of agentic AI projects fail. Not because AI doesn’t work—but because you’re building it wrong. Most…
